You built a RAG (Retrieval-Augmented Generation) demo. On a local machine, with a handful of PDF files, it looked convincing. The answers felt coherent. The system appeared capable.
Then you pushed it to production.
That is usually where the illusion breaks.
Users start reporting that the LLM is “hallucinating” when the real issue is retrieval. Obvious answers go missing even though they exist in the documentation. Irrelevant chunks surface because they are semantically adjacent, not actually useful.
If your RAG system feels unreliable in production, you are not dealing with a model problem first. You are dealing with a retrieval design problem. Most production RAG systems fail because they rely too heavily on vector search and confuse a strong demo with a robust system.
I’ve spent a lot of time building custom AI solutions at Ansezz, and one pattern keeps showing up: a demo proves possibility, but production demands precision.
The “vector noise” trap
The philosophical shift from demo RAG to production RAG is simple: in a demo, semantic resemblance often feels good enough. In production, “good enough” is where failures begin.
Embeddings are useful. They let us map text into vectors and retrieve by meaning rather than exact wording. That is powerful. But semantic similarity is not the same thing as retrieval accuracy.
The problem. Vector search is strong at finding related concepts, but weak at handling specificity.
If a user searches for “Project-X-99 deployment logs,” a vector search might return documents about “Project-A deployment” or “logging best practices” because they are semantically close. It can miss the exact identifier “X-99” because that string carries little semantic weight in a high-dimensional space.
The agitation. Once retrieval drifts, the LLM inherits the drift. The model cannot reason its way out of missing or irrelevant context. You end up paying for tokens that produce confident but unhelpful answers, and users lose trust for a reason that often sits one layer below the model itself.
The solution: hybrid search (vector + BM25)
The move from demo RAG to production RAG usually starts with one realization: meaning alone is not enough. You need semantic retrieval and lexical precision working together. This is hybrid search.
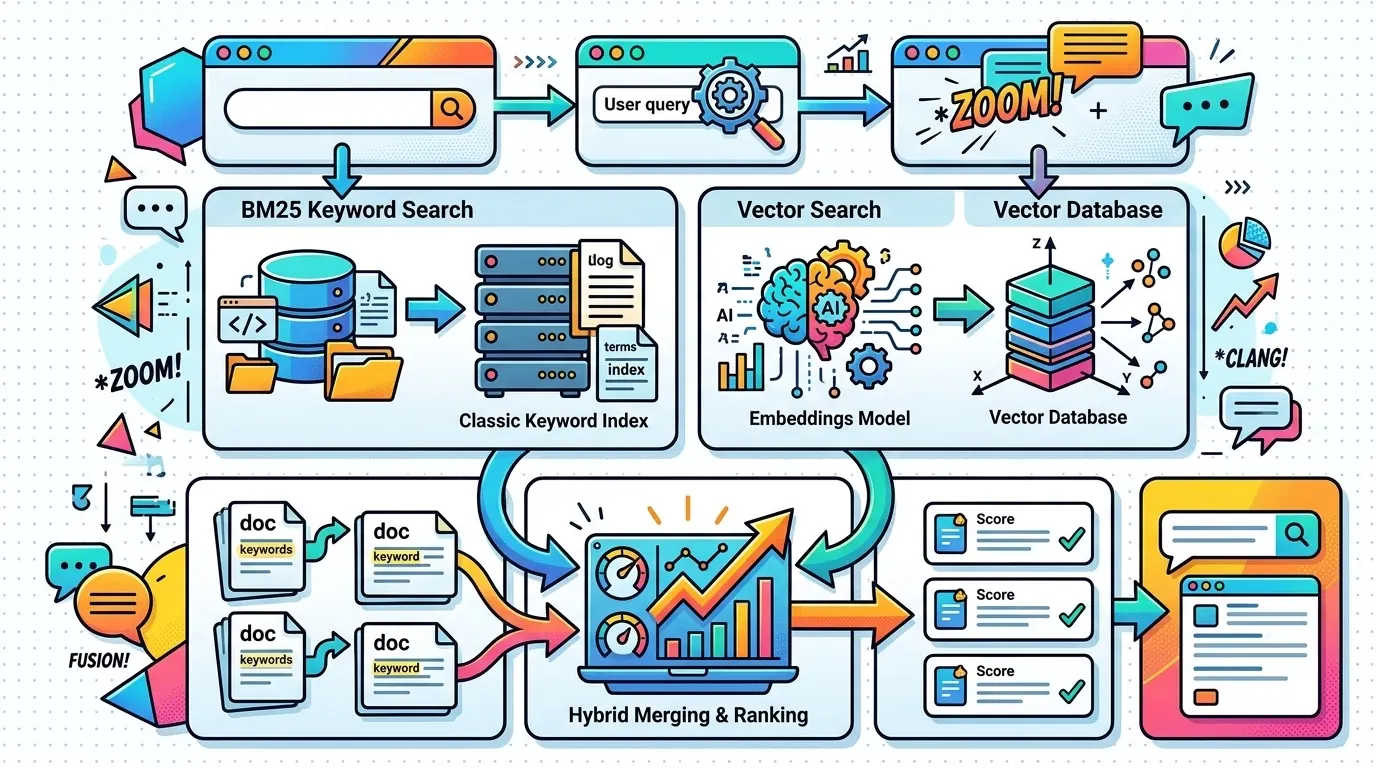
What is BM25?
BM25 (Best Matching 25) is the standard lexical ranking method behind classic search systems. It does not try to infer meaning. It rewards exact terms based on how important they are within a document and across the collection.
Why you need both
- Vector search handles synonyms, multi-lingual queries, and conceptual matching.
- BM25 search handles exact matches, IDs, SKUs, product codes, and technical jargon.
Production systems need both because user questions are rarely pure meaning or pure keyword. They are usually a mix of the two.
Technical insight: reciprocal rank fusion (RRF)
When you run two different retrieval strategies, you also create a new design problem: how should they be combined?
A practical answer is Reciprocal Rank Fusion (RRF). It is simple, reliable, and does not require you to pretend that scores from different retrieval systems are directly comparable.
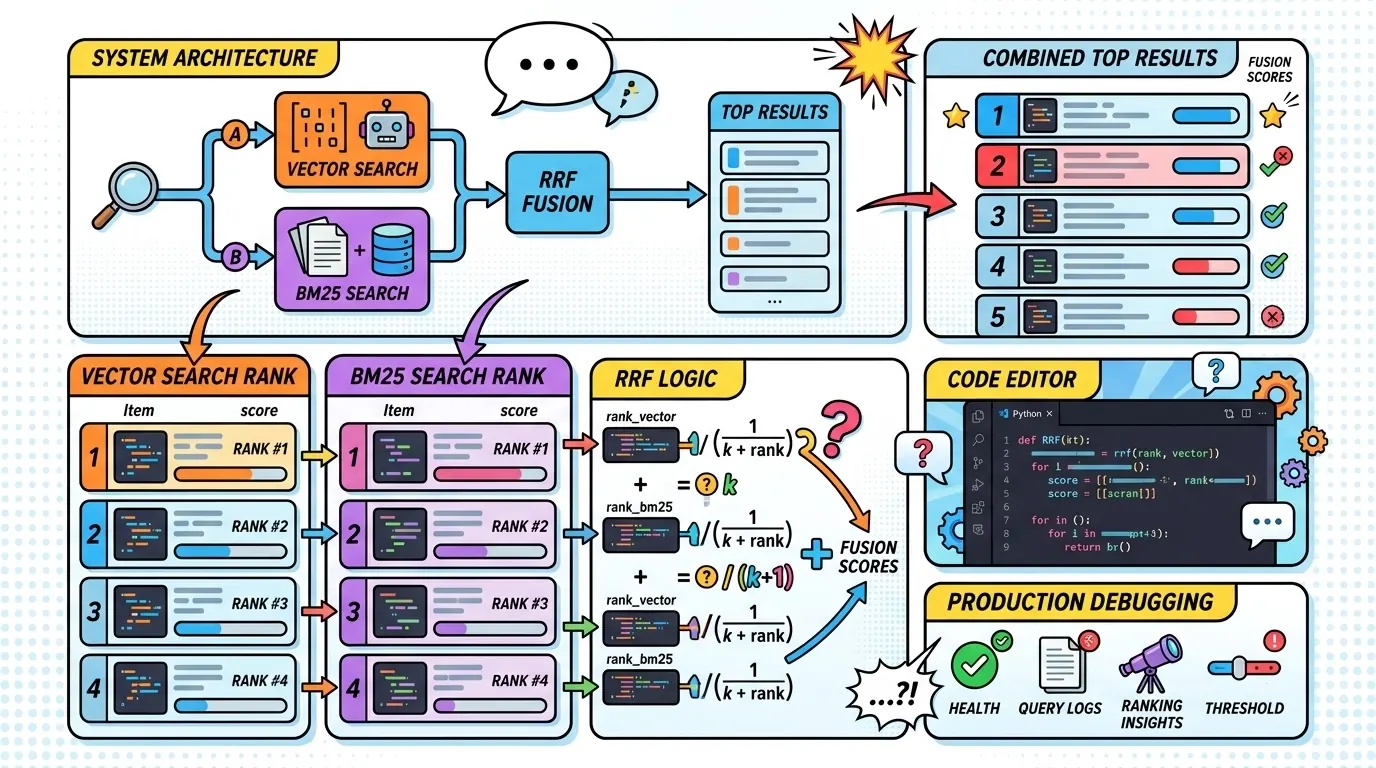
The logic breakdown:
- Assign a score. For every document returned by either search method, calculate a new rank-based score.
- The formula.
score = 1 / (rank + k). Thekvalue (often 60) prevents lower-ranked items from contributing too aggressively. - Sum it up. If a document appears in both the vector and BM25 result sets, its scores are added together.
- Sort. The documents with the highest combined scores are passed to the LLM.
Here’s the minimal PHP version I drop into a Laravel service:
function reciprocalRankFusion(array $resultSets, int $k = 60): array
{
$scores = [];
foreach ($resultSets as $results) {
foreach ($results as $rank => $docId) {
$scores[$docId] = ($scores[$docId] ?? 0.0) + 1 / ($rank + 1 + $k);
}
}
arsort($scores);
return $scores;
}This gives you a cleaner retrieval layer. If a document is semantically relevant and lexically precise, it moves toward the top for a reason.
The “second pass”: using re-rankers
Hybrid search is a strong retrieval foundation, but production RAG usually needs one more layer of judgment.
If you want more precise results, add a re-ranker.
A re-ranker such as Cohere Rerank or BGE-Reranker is a cross-encoder model that evaluates the query and the document together. That matters because relevance is relational. It is not just about what a document contains. It is about whether that document answers this question.
- Step 1. Retrieve the top 50 results using hybrid search.
- Step 2. Pass those 50 results through a re-ranker.
- Step 3. Send only the top 5 re-ranked results to your LLM.
This reduces context stuffing and improves the quality of what reaches the model. In practice, it is one of the clearest differences between a RAG demo and a production RAG system that behaves consistently.
Your production RAG checklist
The problem
A RAG system can feel impressive in a demo and still be structurally weak in production.
The agitation
Once real users, messy documents, and ambiguous queries enter the picture, weak retrieval turns the LLM into expensive guesswork. That is when confidence and correctness start drifting apart.
The solution
To move from demo RAG to production RAG, I focus on a few non-negotiables:
- Stop relying on vector-only search. Add a BM25 layer.
- Implement RRF. Fuse lexical and semantic retrieval without overcomplicating score calibration.
- Tune chunking deliberately. If chunks are too small, they lose context. If they are too large, they add noise. I usually find 512–1024 tokens with a 10–15% overlap works well for technical documentation.
- Add a re-ranker. Refine the final candidate set before anything reaches the LLM.
- Evaluate with RAGAS. Measure faithfulness and relevance instead of trusting intuition.
Building AI is easy. Building reliable AI is hard. It requires a deeper understanding of retrieval, ranking, and context design, not just the ability to connect an API.
If you are looking to build a high-performance SaaS or need help modernizing your digital presence with AI that actually works, check out what I do at Ansezz. I specialize in solving these exact types of technical problems.
Where does your own system still behave like a demo when it should be behaving like production? Get in touch — I read every war story.