Getting a RAG (retrieval-augmented generation) demo working is easy. You take a few PDFs, throw them into a vector database like Chroma or Pinecone, and ask a question. It feels like magic.
But shipping RAG to production is where the magic dies.
I’ve seen too many teams launch a feature only to realize that their users are getting irrelevant answers, waiting 10 seconds for a response, or worse, getting hit with “I don’t know” for questions that are clearly in the documentation. When the “vibe check” fails at scale, your users lose trust.
You’re likely making at least one of these seven structural mistakes that turn a cool demo into a production nightmare. I’ve spent the last few years building custom web applications and AI systems, and I’ve had to fix these same leaks in my own stacks.
Here is how to bridge the gap between “it works on my machine” and a production-grade AI system.
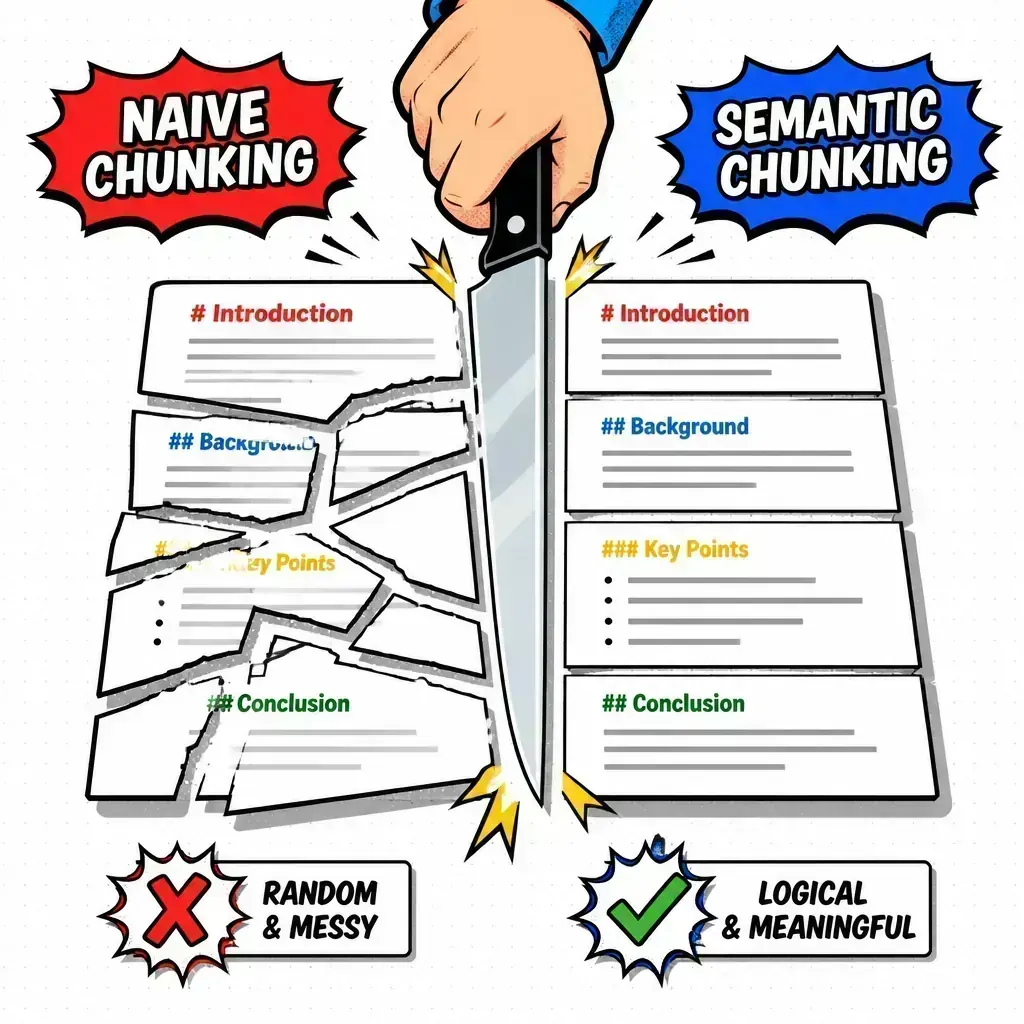
1. Naive chunking is killing your context
Most people start with a simple character-based or token-based splitter. You tell the library to “give me chunks of 500 tokens with a 50-token overlap.”
This is a mistake.
This “naive chunking” treats your data like raw soup. It might cut a sentence in half, split a table in the middle of a row, or separate a coding example from the explanation that precedes it. If the retriever pulls only one of those halves, the LLM has zero chance of giving a correct answer.
The fix: use semantic or structural chunking.
I always recommend chunking based on the actual structure of the document first. Use headers (H1, H2, H3), paragraphs, or even markdown delimiters to ensure related ideas stay together. If you’re working with complex data, consider recursive character splitting that respects newlines and punctuation before falling back to raw token counts.
2. Skipping the reranker step
Vector search is great at finding “roughly similar” stuff, but it’s not a precision instrument. It relies on cosine similarity, which can be easily fooled by documents that share a similar “vibe” but don’t actually contain the answer.
If you’re just taking the top 5 results from your vector store and shoving them into your LLM prompt, you’re leaving quality on the table.
The fix: add a reranking step.
I look at retrieval as a two-stage process. Stage one is the “fast and broad” search where you pull the top 20 or 50 candidates from your vector database. Stage two is using a cross-encoder or a specialized reranking model (like Cohere’s Rerank or BGE-Reranker) to score those 50 candidates against the query more accurately.
The reranker acts like a bouncer at a club. It doesn’t care if a document looks “okay.” It only lets in the ones that are actually relevant to the question.

3. Ignoring embedding drift and versioning
This is the silent killer. I’ve seen teams upgrade their embedding model from text-embedding-ada-002 to text-embedding-3-small without re-indexing their entire database.
Suddenly, the vectors being generated for new queries don’t “line up” with the vectors stored in the index. The similarity scores go haywire. Even worse is when you change the preprocessing logic (like how you format the chunks) but keep the old vectors.
The fix: pin your models and version your index.
Treat your embedding model like a database schema. If you change the model, you must re-index. I always include the model name and version in the metadata of every index I build. This way, if I need to test a new model, I can run them side-by-side without breaking the production flow. My experience in cloud infrastructure has taught me that consistency is better than a “better” model that doesn’t match its data.
4. The “needle in a haystack” latency problem
Everyone wants more context. We see context windows of 128k or even 1M tokens and think, “great, I’ll just give the LLM everything!”
This is a trap for two reasons. First, latency — feeding 50k tokens of context into an LLM can make your response time balloon to 20 or 30 seconds. Second, models still struggle with “lost in the middle” problems: they tend to ignore information buried in the center of a massive context window.
The fix: optimize your latency budget.
I start with a “latency budget.” If the user expects a response in under 2 seconds, I can’t afford to send 20 chunks. I limit my retrieval to the top 3–5 high-quality chunks and use streaming as soon as the first token is ready.
If you need more data, consider using a multi-step approach: use a cheaper model to summarize the retrieved chunks before passing the refined info to your main model.

5. Forgetting about hybrid search
Vector search is terrible at finding specific keywords or unique identifiers. If a user asks for “error code XF-904,” a vector search might return documents about “general error handling” because the “vibe” is similar. But it might miss the one specific document that actually mentions “XF-904.”
The fix: implement hybrid search.
I always combine dense vector search with traditional sparse search (like BM25). By blending these two results using something like Reciprocal Rank Fusion (RRF), you get the best of both worlds. You get the semantic understanding of vectors and the keyword precision of full-text search. This is non-negotiable for enterprise search or technical documentation.
6. Failing to filter by metadata
If your RAG system contains documents for different clients, versions, or dates, pure vector search will betray you. You might ask about “API changes in 2024” and get results from 2022 because they share similar keywords.
Relying on the LLM to “ignore” the wrong dates in the context is a waste of tokens and a recipe for hallucinations.
The fix: use hard metadata filters.
Before the vector search even happens, apply filters. If you know the user is looking for “v2” of your documentation, filter the vector query to only include chunks with version: '2'. This drastically reduces the search space and improves accuracy. I use this heavily when building Shopify apps where data must be strictly siloed by shop ID.
7. Vibe-based evaluation
How do you know your RAG stack is getting better? Most devs just ask a few questions, see that the answer looks okay, and ship it.
This is called “vibe-checking,” and it doesn’t work. When you change a prompt or a chunk size, you might improve one answer while breaking ten others you didn’t check.
The fix: build a golden evaluation set.
I use the Ragas framework or simple LLM-as-a-judge patterns to run automated evals. I maintain a “golden set” of 50–100 questions with ground-truth answers. Every time I change the architecture, I run the eval and look for three metrics:
- Faithfulness — is the answer actually derived from the context?
- Answer relevance — does it answer the user’s question?
- Context precision — are the retrieved chunks actually useful?
Practical takeaways for your stack
- Start with metadata — don’t let the vector database guess. If you have categories or dates, use them as hard filters.
- Rerank by default — it’s the single biggest quality jump you can make for the lowest effort.
- Monitor retrieval, not just generation — if your retriever fails, the best LLM in the world can’t save you. Log your top-k retrieval results separately.
- Don’t over-engineer — sometimes a simple long-context prompt is better than a complex agentic workflow. Measure before you add complexity.
Building production RAG is a game of millimeters. It’s about cleaning your data, pinning your models, and actually measuring what’s happening under the hood.
I’ve spent years moving from “it works” to “it’s reliable.” If you’re struggling with a specific part of your AI pipeline, what’s the one thing that’s currently keeping you from hitting that “deploy” button?
Drop a comment or reach out if you’re hitting a wall with your architecture. 🤘