You built a cool chatbot. It works great on your local machine until you feed it 50,000 internal documents. Suddenly, it’s hallucinating. It’s slow. It’s pulling data from three years ago when you specifically asked for last week’s report.
Building a Retrieval-Augmented Generation (RAG) system sounds like a weekend project. But once you move past the “hello world” stage, you hit the database wall. Choosing the wrong vector store early on is a silent killer. It leads to high latency, soaring cloud costs, and a painful migration six months down the line when your data outgrows your infrastructure.
I’ve spent over a decade building custom web applications and scaling cloud infrastructure. I’ve seen teams get paralyzed by the sheer number of options in the AI ecosystem. You don’t need a perfect database. You need the right tool for your specific scale and team.
Let’s break down the 2026 vector database landscape so you can stop scrolling and start shipping.
Why the database matters in RAG
An LLM like Claude or GPT-4 is a genius without a memory. RAG gives it that memory. Your vector database is the librarian. If the librarian is slow or loses books, the genius can’t do its job.
When we talk about RAG stacks, we’re looking for three things:
- Latency — can it find the right “memory” in under 50ms?
- Hybrid search — can it search by meaning (vectors) and exact keywords (full-text)?
- Developer experience — how much time are you going to spend on DevOps?

The contenders: which one is yours?
1. pgvector — the “I already have a database” choice
If you are already running Postgres for your web applications, pgvector is usually your first stop. It’s not a new database. It’s an extension that adds vector support to the database you already trust.
It’s perfect if you have under 10 million vectors. You get ACID compliance, easy backups, and your relational data stays right next to your embeddings. No new infra. No new security audits.
Pros
- Zero new infrastructure if you use Postgres.
- Perfect for joining vector data with user metadata.
- Huge ecosystem support (Laravel, Django, Node.js).
Cons
- Scaling to 100M+ vectors requires serious server muscle.
- Hybrid search requires manual tuning with Postgres full-text search.
2. Pinecone — the “I want zero ops” choice
Pinecone is the gold standard for managed service. It’s a serverless vector database. You don’t manage clusters. You don’t tune indexes. You just send vectors and get results.
In 2026, Pinecone is the go-to for teams that want to scale from zero to a billion vectors without hiring a dedicated DevOps engineer. Their serverless architecture means you only pay for what you use.
Pros
- Truly managed. Pick a region and go.
- World-class performance and low latency.
- Great enterprise features like SOC2 compliance.
Cons
- It’s a black box. You can’t self-host it.
- Costs can scale quickly if you have high write/read volume.
3. Weaviate & Qdrant — the hybrid powerhouses
If your RAG app needs to combine semantic search with old-school keyword search, these two are the leaders. Weaviate and Qdrant are built from the ground up for high-performance vector retrieval.
Weaviate excels at “out-of-the-box” hybrid search. Qdrant, written in Rust, is incredibly fast and efficient with memory. Both offer open-source versions and managed cloud options.
Pros
- Best-in-class hybrid search (BM25 + Vector).
- Flexible hosting (self-hosted Docker or managed cloud).
- Highly optimized for filtering (e.g., “find documents from ‘2025’ that talk about ‘security’”).
Cons
- More operational overhead than Pinecone.
- Requires learning a new database API.
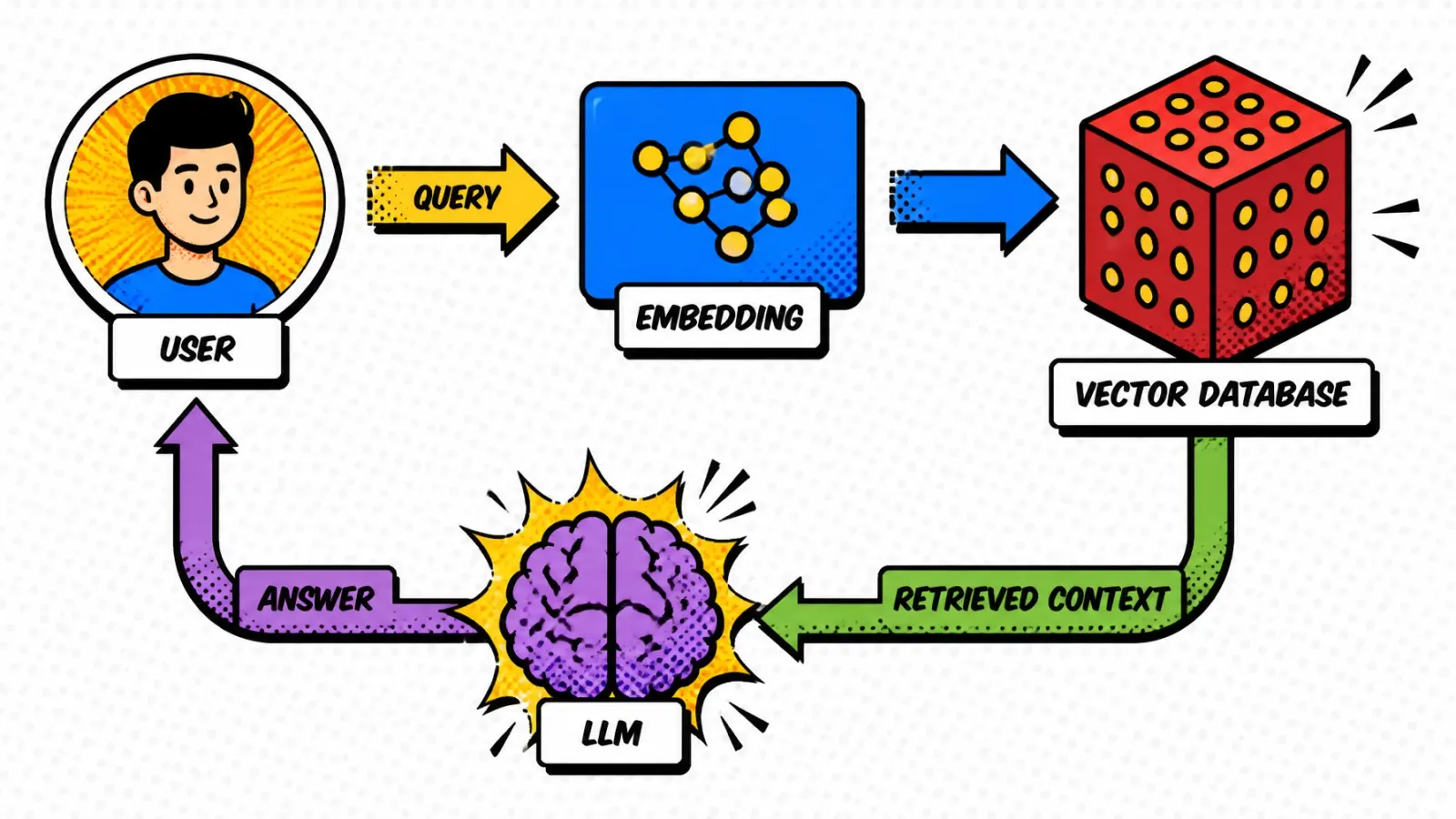
How to choose: the engineering trade-offs
Picking a database isn’t about finding the “best” one. It’s about matching the tool to your engineering constraints.
Factor 1: the “billions” problem
Most startups don’t have a billion vectors. They have a few thousand PDFs. If you’re in the sub-1M range, pgvector is almost always the right answer. It’s simple and it works.
If you are building something like a global legal search engine or a massive e-commerce recommendation system, you need the distributed architecture of Milvus or Pinecone. Don’t build a massive distributed system if you don’t have a massive amount of data.
Factor 2: hybrid search is non-negotiable
Pure vector search is actually pretty bad at finding specific technical terms. If you search for “PHP 8.4 features,” a pure vector search might give you general “PHP” articles. A hybrid search combines the “vibe” of the vector with the “exactness” of a keyword search.
If search quality is your #1 metric, look at Weaviate or Qdrant. They handle the blending of these two search types natively.
Factor 3: the “DevOps” tax
I’m a huge fan of cloud infrastructure and deployment. But I also know that every new piece of infra you add to your stack is another thing that can break at 3 AM.
If you have a small team, lean on managed services like Pinecone or Zilliz. If you have a strong infra team and want to save on cloud margins at high scale, self-hosting Qdrant on a tool like Coolify or Kubernetes is the move.
Implementing pgvector with Laravel
Since I work a lot with custom web development using Laravel, I want to show you how easy this looks in practice. You don’t need a PhD in math to run a vector query.
// finding the most relevant document chunks
$embedding = Ai::embed($query); // get vector from OpenAI/Claude
$results = Document::query()
->select('content')
->orderByRaw('embedding <=> ?', [$embedding]) // the <=> operator is pgvector's magic
->limit(5)
->get();That snippet is essentially the core of a RAG system. You find the content, send it to the LLM, and get a grounded answer.
Three practical tips for your RAG stack
Before you commit to a database, keep these three things in mind. They will save you weeks of refactoring.
1. Index early, but not too early. Vector indexes like HNSW are fast for searching but slow for inserting data. If you are doing a massive initial data load, insert your vectors first, then create the index. It’s the difference between minutes and hours.
2. Normalize your vectors. Make sure your embedding model and your vector database are on the same page. If you use cosine similarity, normalize your vectors. It keeps your results consistent and prevents weird ranking bugs.
3. Keep the metadata lean. It’s tempting to store the entire JSON object of a document inside your vector database. Don’t. Store the vector and a simple ID. Keep the heavy data in your primary database (like Postgres). This keeps your vector index small and fast.
My personal rule of thumb
I’ve built systems for startups and established businesses. Here is how I usually guide them:
- Default to pgvector. It’s the path of least resistance for most web apps.
- Move to Pinecone if you need high performance and don’t want to manage servers.
- Choose Weaviate if your application relies heavily on complex hybrid search and metadata filtering.
The “right” stack is the one that lets you ship your AI features today, not the one that looks the best on a benchmark chart.
Are you building a RAG system right now? What’s the biggest hurdle you’ve hit with your data retrieval?
Drop a line or reach out. I’d love to hear your war stories.
Summary takeaways
- pgvector is king for teams already on Postgres.
- Pinecone is the best zero-ops solution for scaling.
- Hybrid search (keyword + vector) is usually better than vector search alone.
- Keep your architecture simple. Don’t over-engineer for “billions” of vectors if you only have thousands.