Every time I have to build a custom integration for a new tool, a little piece of my developer soul dies. It is a maintenance nightmare that never ends. We have reached a point where building the actual product is often faster than setting up the pipes to make it work with our data.
If you have spent any time building agentic workflows and vibe coding, you know exactly what I am talking about. You have an LLM like Claude that is incredibly smart but essentially locked in a room with no windows. To give it context, you have to manually copy-paste code, export CSV files, or spend three days writing a brittle wrapper for a third-party API just so your assistant can “see” your work.
This fragmentation is the biggest bottleneck in modern software development. We have powerful models, but they are isolated from our local files, our databases, and our production logs. It is like having a world-class architect who isn’t allowed to visit the construction site. They are just guessing based on the photos you decide to send them.
Enter the Model Context Protocol — or as I have been calling it: the USB port for LLMs.
The fragmentation tax is killing your productivity
The problem is simple but massive. Every AI application — whether it is Claude Desktop, a custom agent, or an IDE extension — wants to talk to your data. On the other side, every data source — your GitHub repos, your Postgres databases, your Slack channels — has its own specific API and authentication flow.
Without a standard, we are stuck in an M×N problem. If you have 5 AI apps and 10 data sources, you need 50 different integrations. This is why most “AI-powered” tools feel shallow. They only support a few basic integrations, and if you want to use your internal company data, you are back to writing custom glue code.
This agitation is real. We are wasting hours building the same connectors over and over again. We are worried about security because every new integration is another potential leak. And we are frustrated because the “magic” of AI disappears the moment we hit a data silo.
The solution: MCP as a universal standard
Claude MCP (Model Context Protocol) is the first serious attempt to standardize how AI applications discover and interact with data and tools. Instead of building a specific connector for every model and every tool, you build an MCP server.
This server acts as a translator. It sits between your data and the AI, exposing a consistent interface that any MCP-compliant host (like Claude Desktop) can understand. It is exactly like the USB standard. It doesn’t matter if you are plugging in a mouse, a keyboard, or an external drive. The protocol is the same, so it just works.
This shifts the entire paradigm of context-aware agents. Instead of hard-coding logic into the agent, you simply “plug in” the servers you need.
How the architecture actually works
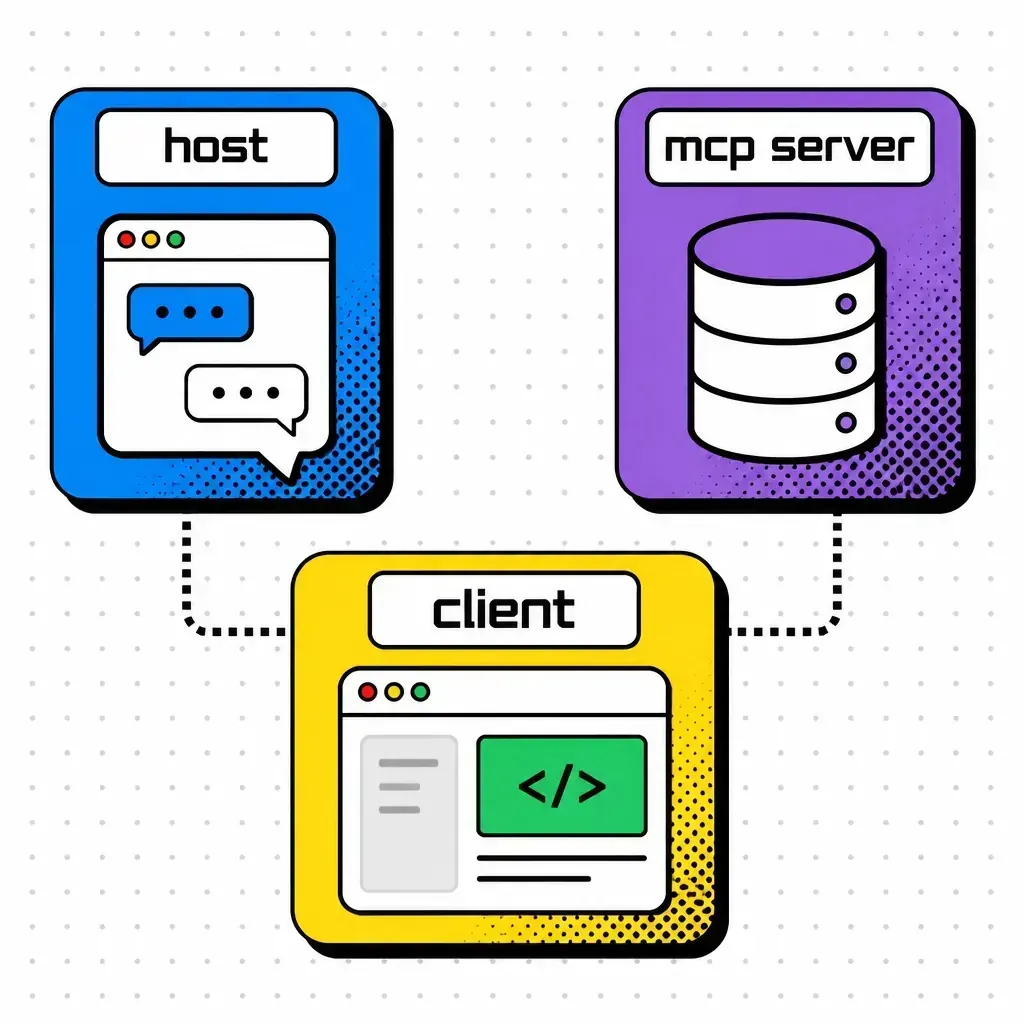
There are three main players in the MCP ecosystem:
- The host — this is the environment the user interacts with. It could be Claude Desktop, a terminal, or an IDE like Cursor. The host is responsible for managing the lifecycle of the connection.
- The client — this is the part of the host that speaks the protocol. It does the “handshake” with the server to find out what it can do.
- The server — this is a lightweight program that provides context (resources), actions (tools), and prompt templates.
For example, if I want Claude to have access to my local project files, I run a local MCP server that exposes those files as “resources.” The host (Claude Desktop) asks the server: “what do you have?” The server replies: “I have these 10 files and a tool to run grep searches.”
The model can then decide to call the “grep” tool whenever it needs to find a specific function definition. I didn’t have to write a single line of logic inside Claude to make that happen. I just connected the server.
Modularity and the MCP server ecosystem
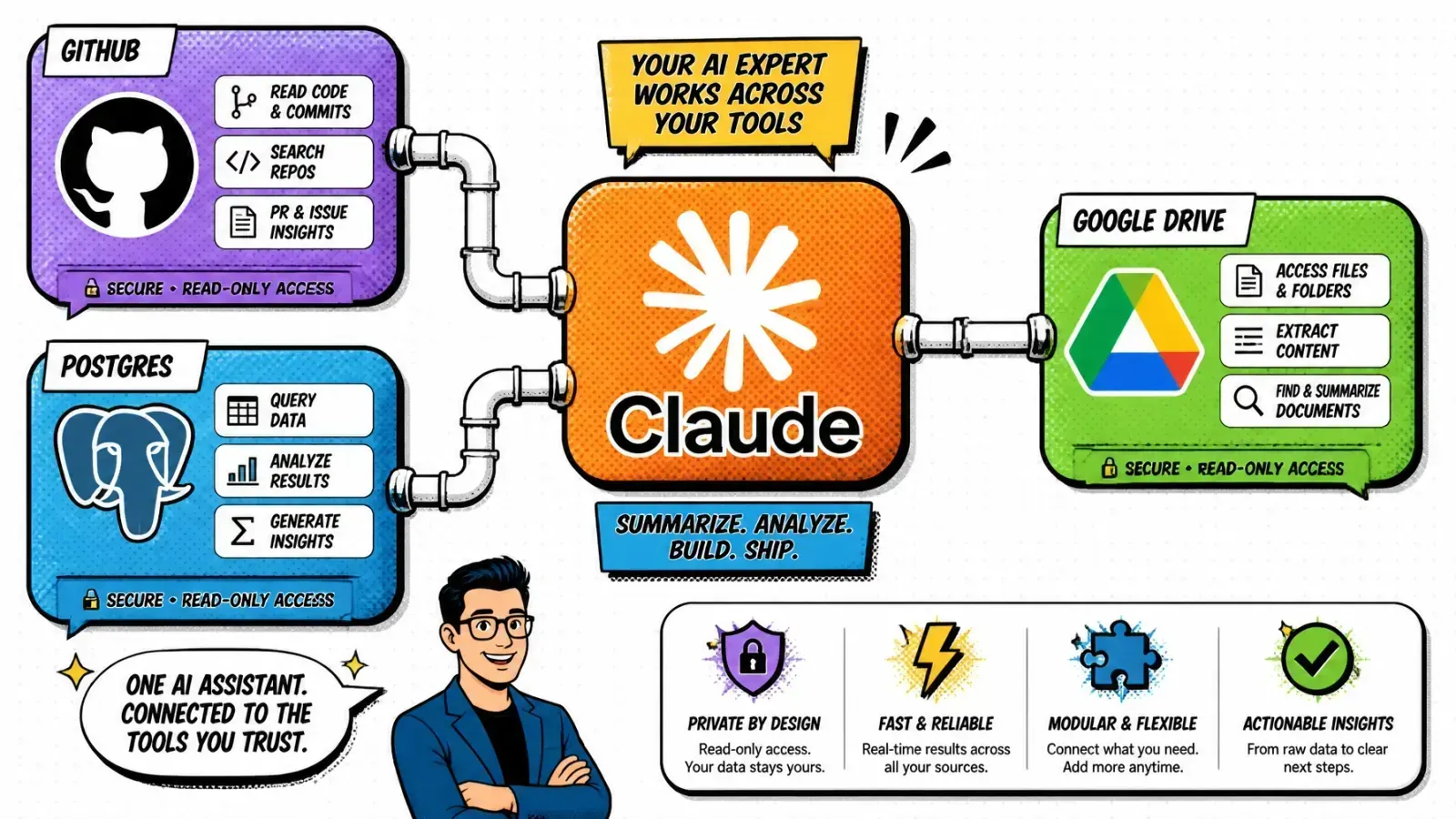
The beauty of this modularity is that once a server is built, anyone can use it. The community has already started building servers for everything you can imagine. I have been using a few in my daily workflow that have completely changed how I code:
- Postgres MCP — I can point Claude at a local or remote database. It can inspect schemas and even run queries to help me debug data issues without me leaving the chat.
- GitHub MCP — this allows the model to search through my repositories, list issues, and even create pull requests. It is like having a junior dev who actually knows where the code is.
- Google Drive MCP — perfect for when I need to cross-reference technical documentation stored in docs with the actual implementation in my IDE.
This also solves a massive pain point in agentic commerce for Shopify. Imagine an agent that can talk directly to your Shopify store via MCP to check inventory levels or update product descriptions in real-time, all while maintaining a secure, standardized connection.
Security first: the sandbox model

The biggest question I get when I talk about connecting dev tools to an LLM is: “is it safe?”
Security is baked into the design of MCP. Because the server is a separate process, it runs in its own sandbox. It only has access to the specific resources you grant it.
For local servers, the protocol typically uses stdio (stdin/stdout). This means the server can only talk to the host through a very narrow pipe. It doesn’t have open network ports listening for connections. It only exists as long as the host is running it.
For remote servers, MCP uses OAuth 2.1. This allows for fine-grained permissions. You can authorize a GitHub MCP server to only read public repositories, or a database server to only access specific tables.
This is a huge improvement over the “give me your master API key” approach that we have seen in the past. We can now treat AI tools with the same “least privilege” mindset we use for any other service in our stack. This is especially important when you are trying to avoid RAG mistakes in production, where data leakage is a top-tier risk.
Why I am betting on MCP
I have been a developer for over a decade, and I have seen plenty of “standards” come and go. What makes MCP different is its simplicity and its backers. Anthropic has made this open source because they realize that the more context a model has, the more valuable it becomes.
We are moving toward a world of “agentic” software development. In this world, we don’t just use AI to write snippets of code. We use AI as an orchestrator that can reach into our cloud infrastructure on GCP, check our Docker logs, and suggest fixes for a failing Laravel app.
Without a protocol like MCP, that vision is impossible to scale. It would be too expensive and too risky to build. But with MCP, we are building a world where tools are plug-and-play.
Practical takeaways for senior engineers
If you are ready to start experimenting with this, here is what I recommend:
- Install the Claude Desktop app — it is currently the most mature host for MCP.
- Try the filesystem server — this is the easiest way to feel the power. Give Claude access to a specific folder and watch it navigate your codebase.
- Don’t build, search first — check the official MCP GitHub repository. There are already servers for Brave search, Postgres, Slack, and more.
- Think in tools, not just prompts — start thinking about what “tools” your internal systems could expose. If you have a custom admin panel, could it be an MCP server?
Connecting your dev tools to an LLM isn’t just about speed. It is about reducing the cognitive load of switching between tabs, terminals, and documentation. It allows you to stay in the “flow” longer.
Are you ready to stop copy-pasting your code into a chat box and start connecting your tools directly to the brain? What is the one internal tool you wish you could “plug in” to Claude right now? Drop a note via contact — let’s figure it out. 🤘