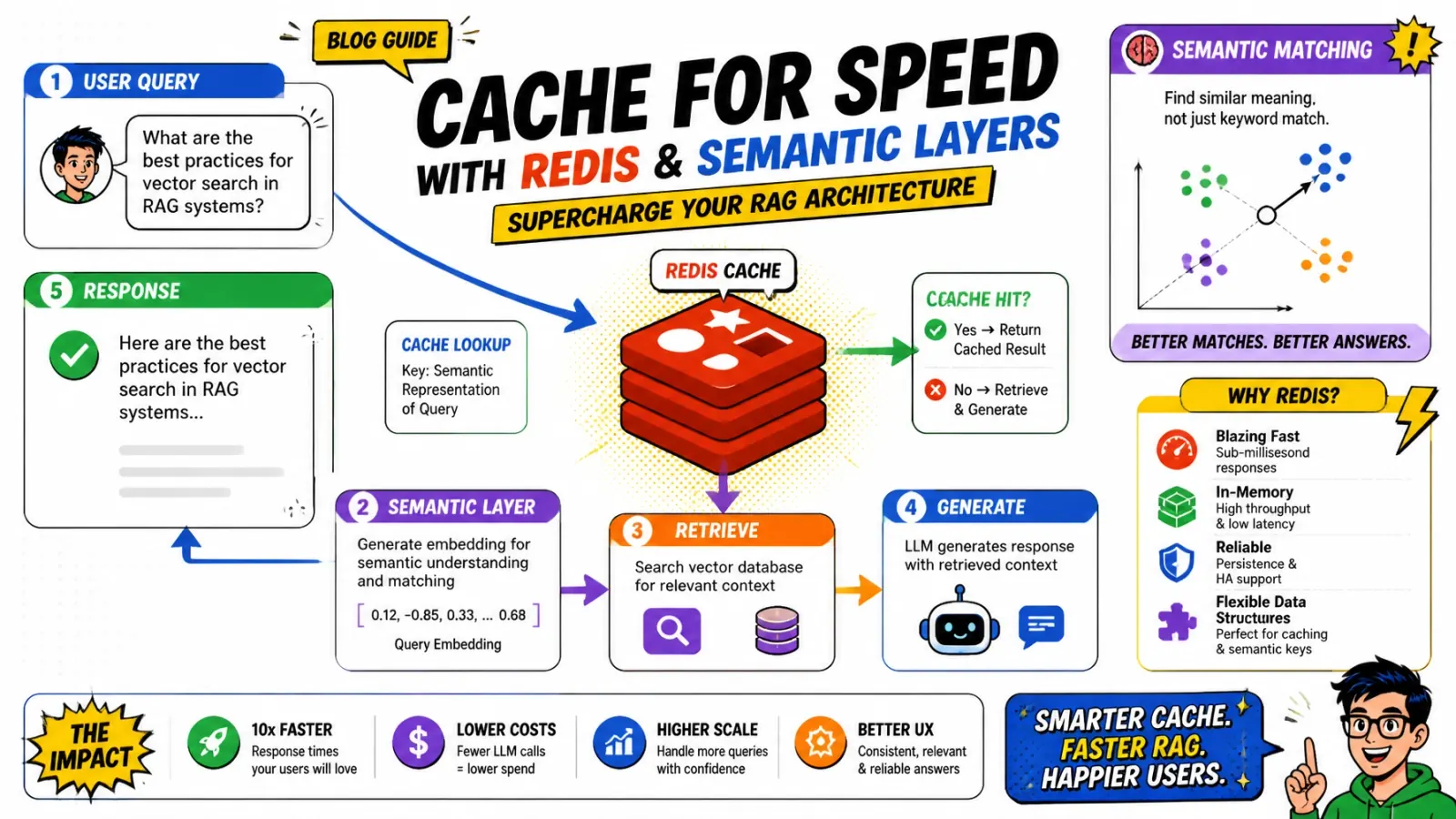
You finally shipped your RAG pipeline. It works. The retrieval is accurate. The LLM is snappy. But then you look at your cloud bill and your P99 latency. Every single query — even “what are your shipping times?” asked for the tenth time — triggers a full chain of embedding, vector search, and an expensive LLM call.
At scale, this is a disaster. You are essentially paying for the same computation over and over again. Your users are waiting two seconds for answers that should take twenty milliseconds. Your “denial of wallet” risk is through the roof.
The solution isn’t a bigger model or a faster vector DB. It’s a smarter cache. I’m talking about semantic caching with Redis. It cuts latency from hundreds of milliseconds to single digits and slashes your API costs by up to 80 percent.
Here is how I build these systems to handle production traffic.
The two-tier cache architecture
Standard caching relies on exact matches. If a user asks “How do I reset my password?” and another asks “how do i reset my password”, they might hit the same key if you normalize the string. But if the second user asks “Can you help me change my password?”, a traditional cache fails.
In a modern RAG stack, I use a two-tier approach.
- Exact cache — a simple key-value store in Redis. I normalize the query (lowercase, trim, strip punctuation) and hash it. It’s your first line of defense. It costs almost nothing and has zero false positives.
- Semantic cache — if the exact cache misses, I embed the query and look for “near enough” matches in a Redis vector index. If I find a previous question with a similarity score of 0.95 or higher, I serve that cached response instead of hitting the LLM.
This architecture ensures that you never do the heavy lifting twice for the same intent.
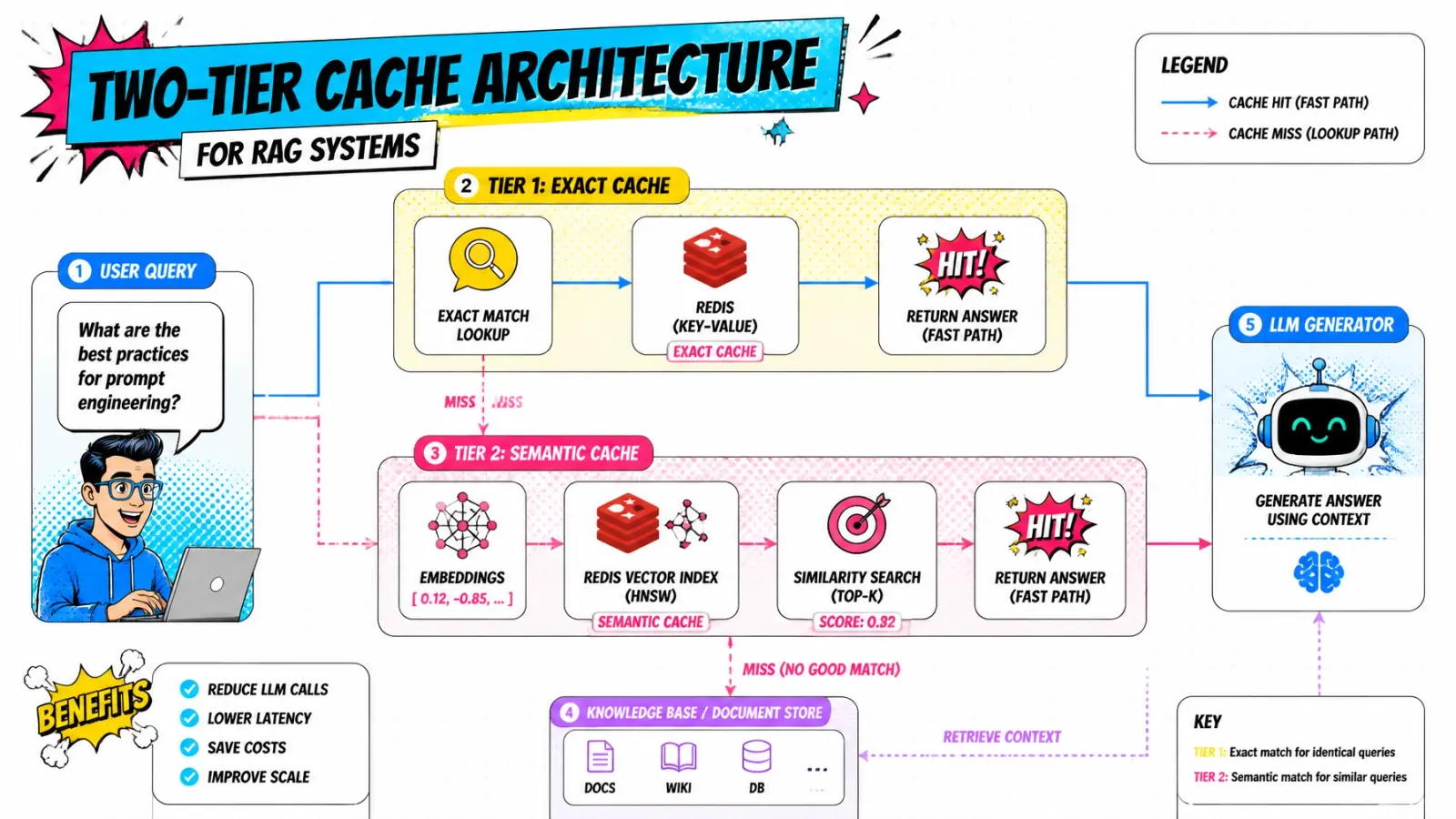
Why Redis is the king of semantic caching
Most developers think of Redis as just a key-value store. But with the Redis Vector Library (RedisVL), it becomes a high-performance vector database.
Why use Redis for this instead of your main vector DB like Pinecone or Weaviate?
Latency.
Your main vector DB is likely optimized for searching through millions of document chunks. Your semantic cache is much smaller — it only stores recent queries and answers. By co-locating this cache in Redis, which likely already sits in your application tier, you reduce network hops.
I typically see vector lookups in Redis finish in under 5ms. Compare that to an embedding API call that takes 100ms and an LLM generation that takes 1500ms. The math is simple.
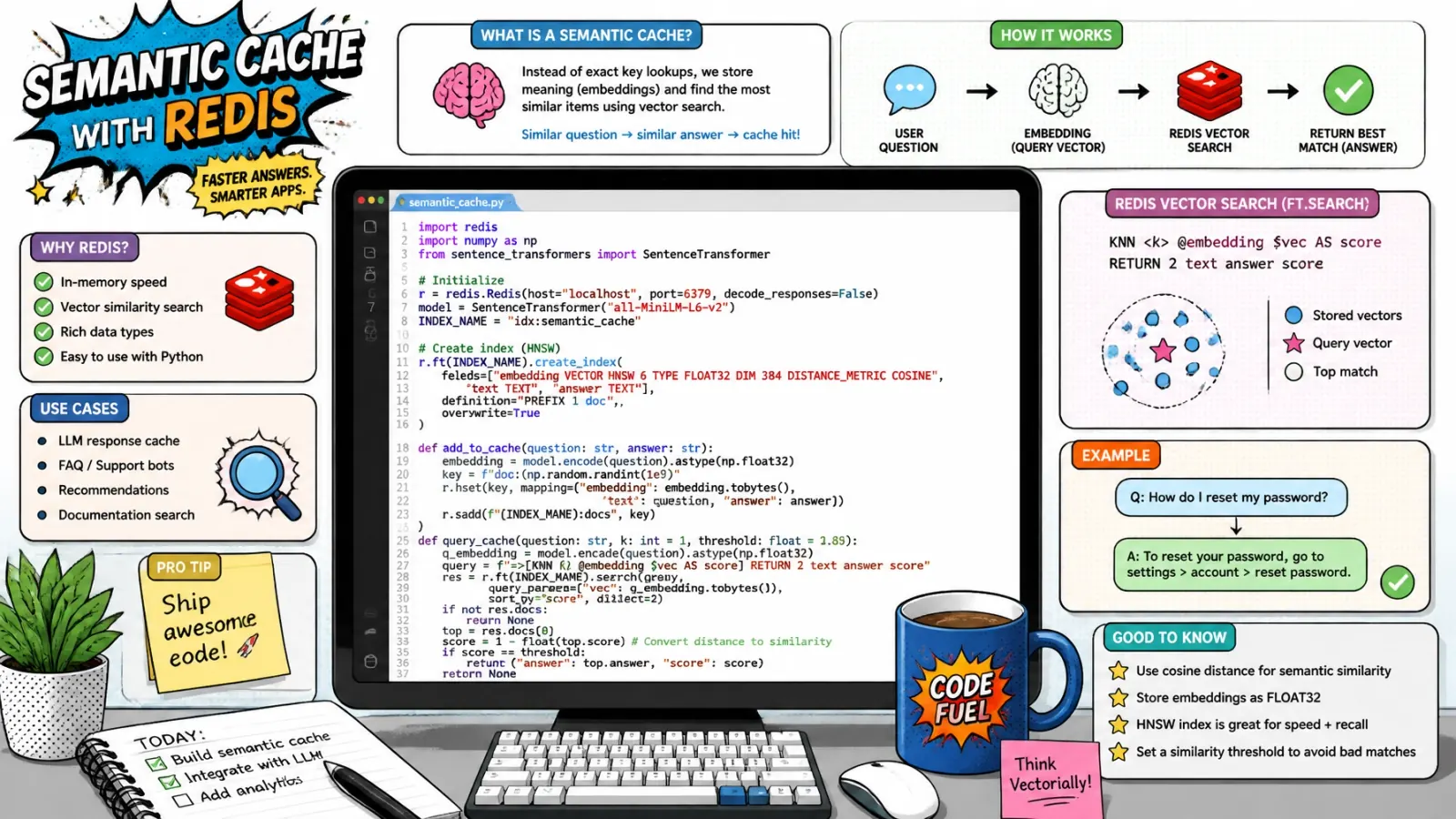
Implementing the semantic layer
The trick to a good semantic cache is the similarity threshold. Too low, and you give users wrong answers (the “semantic trap”). Too high, and you never get a cache hit.
I usually start with a distance threshold of 0.1 for cosine distance, which translates to roughly 90 percent similarity. You can implement this quickly using the RedisVL extensions.
from redisvl.extensions.llmcache import SemanticCache
# Initialize the cache with a conservative threshold
llm_cache = SemanticCache(
name="production_rag_cache",
redis_url="redis://localhost:6379",
distance_threshold=0.1,
)
# Check for a hit
query = "how do i update my billing info?"
hit = llm_cache.check(prompt=query)
if hit:
return hit[0]["response"]
# If miss, run full RAG and then store
# response = run_rag_pipeline(query)
# llm_cache.store(prompt=query, response=response)This simple wrapper handles the embedding of the incoming query, the vector search in Redis, and the logic for returning the most relevant cached response.
Avoid the semantic trap: context and versioning
Semantic caching is powerful but dangerous if you aren’t careful. If your underlying data changes, your cache might still be serving old, incorrect information.
I always include a context_version in my cache keys or metadata. If I re-index my product catalog or update my documentation, I bump the version. The cache immediately starts missing for old entries, forcing a refresh with the new data.
Another trap is tenant isolation. If User A asks “what is my balance?”, you absolutely cannot serve that cached response to User B. I solve this by partitioning the cache:
- Use namespaces —
cache:tenant_id:query_hash - Include metadata — add
tenant_idto the vector index filters.
This ensures that semantic matches only happen within the correct security boundary. For more on building secure, multi-tenant systems, check out my thoughts on Laravel multi-tenancy which shares similar isolation principles.
Managing TTL and staleness
In a standard cache, you just set an expiry of 3600 seconds and forget it. With a semantic cache, I prefer a tiered TTL strategy.
- Exact matches — 1 hour TTL. If the user asks the exact same thing, they probably want the exact same answer.
- Semantic matches — 4 hour TTL. These are more expensive to generate, so we want to keep them longer, but we also include a “last validated” timestamp.
- Proactive invalidation — if my Shopify store updates a product price, I trigger a Redis worker to purge all cache entries related to that product ID.
This hybrid approach keeps the system responsive without serving stale data. I’ve written about similar event-driven patterns here if you want to dive deeper into how to handle these updates at scale.
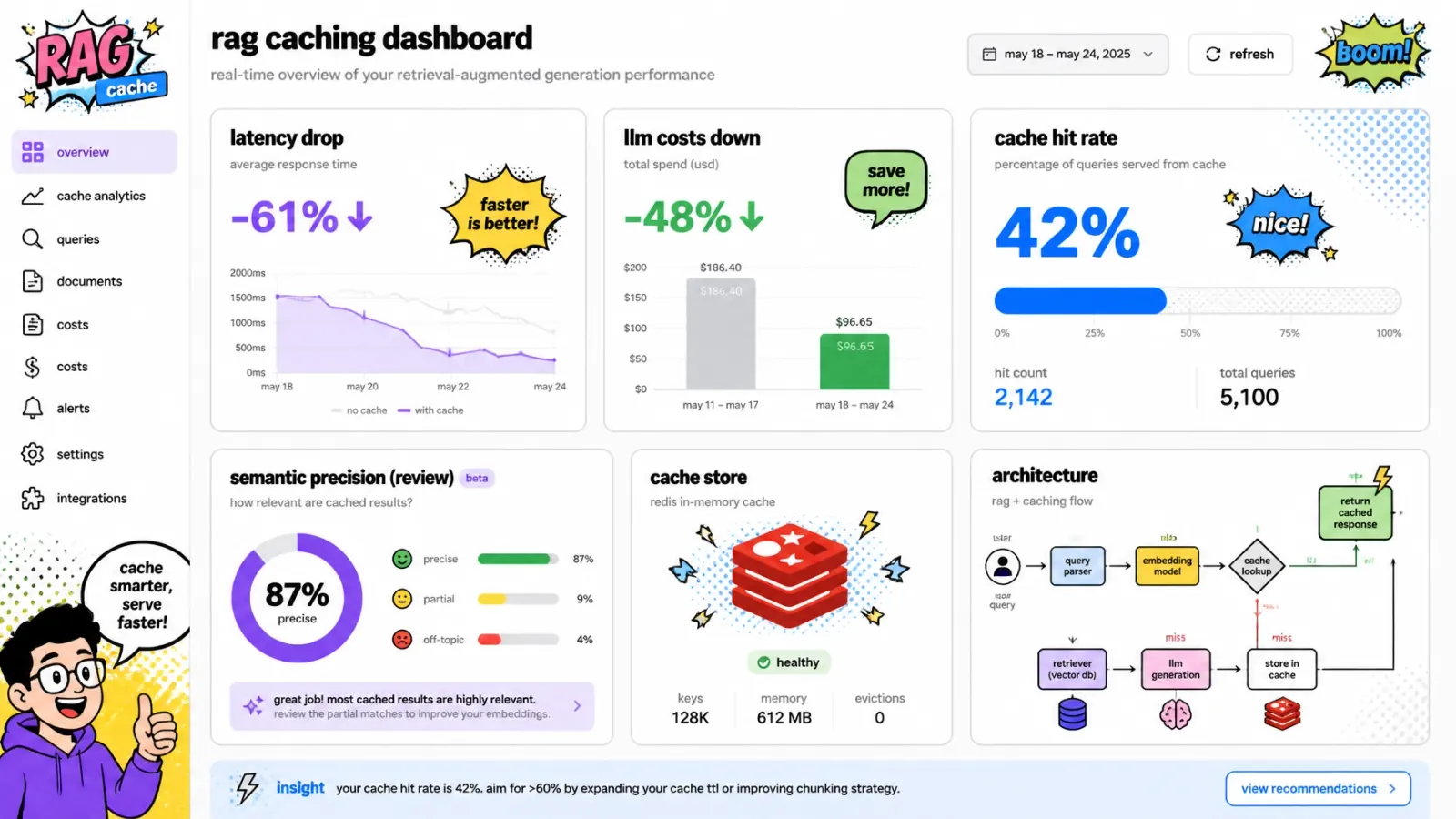
Measuring success: precision and recall
Don’t just turn on the cache and walk away. You need to monitor two specific metrics:
- Cache hit rate — what percentage of queries are being handled by Redis? I aim for 30–50 percent for general FAQ-style bots.
- Semantic precision — are the cached answers actually correct?
I log every semantic hit along with its similarity score. Once a week, I sample hits with scores between 0.85 and 0.92 and manually review them. If I see too many “near misses” that are actually different questions, I tighten the threshold.
Final takeaways for senior engineers
Implementing Redis as a semantic layer isn’t just about speed. It’s about making your AI systems sustainable. If you are serious about moving from a prototype to a production-ready SaaS, caching is not optional.
Here is your checklist for next week:
- Install
redisvland set up a basic vector index in your dev environment. - Implement a two-tier lookup (exact then semantic).
- Set your distance threshold conservatively (start at 0.05 or 0.1).
- Add a
tenant_idorcontext_versionto your metadata to avoid cross-talk. - Monitor your hit rate and watch your API bill drop.
Building in public means sharing the war stories, not just the successes. For more technical deep dives into modern architecture, I suggest looking at 7 RAG mistakes in production to see what else might be slowing you down.
What is the one query in your system that keeps hitting your LLM unnecessarily? Drop a note via contact — let’s figure out if a semantic cache would have caught it. 🤘


