You just scaled your RAG application to a hundred concurrent users. Suddenly, your latency spikes. Some users get their answers in two seconds, while others are staring at a loading spinner for thirty. You check your load balancer and it says everything is fine. CPU is at 40%. RAM is stable. But your GPUs are screaming, and your P99 latency is in the gutter.
The problem is that you are treating your AI models like traditional web servers. Sending a 4,000-token prompt to the same GPU that is currently generating a 50-token summary is a recipe for disaster. Round-robin routing is a relic of the past when it comes to LLM inference. If you don’t account for the unique way GPUs handle compute and memory, you aren’t just wasting money. You are killing your user experience.
The solution isn’t just “more GPUs.” It is building a load balancer that actually understands what is happening inside the model. We need to talk about GPU-aware routing, prefill vs decode disaggregation, and why your KV cache is the most valuable asset in your stack.
Why round-robin is a trap for LLMs
In traditional software development, a request is a request. Whether it’s a GET /users or a POST /orders, the variance in resource consumption is usually predictable and small. Standard load balancers like Nginx or HAProxy work great here. They look at basic health checks and send traffic to the next available worker.
AI is different. A single request to an LLM has a massive variance in “weight.” One user might ask “what is 2+2?” while another uploads a 50-page PDF and asks for a deep analysis. If your load balancer sends both to the same GPU, the heavy request will hog the compute resources, forcing the light request to wait in a queue.
This is why CPU-based metrics are useless. A GPU can be at 100% utilization while performing very different types of work. Some work is compute-bound, meaning it needs raw processing power. Other work is memory-bound, meaning it is limited by how fast data can move in and out of VRAM. To solve this, we have to look deeper into the inference lifecycle.
Prefill vs decode: the performance gap
LLM inference happens in two distinct phases. Understanding the difference between them is the “aha!” moment for GPU load balancing.
The first phase is prefill. This is when the model reads your entire prompt and processes all the tokens at once. It is a heavy, compute-intensive task that builds something called the KV cache (key-value cache). Prefill loves big batches and high-performance tensor cores. It is where the “heavy lifting” happens.

The second phase is decode. This is where the model generates the response one token at a time. Each new token only needs to look at the previously generated tokens and the KV cache. This phase is surprisingly light on compute but incredibly heavy on memory bandwidth. It is slow and long-lived.
When you mix these two on the same GPU without a smart scheduler, the “prefill” of a new request will often pause the “decode” of existing requests. This causes the jittery, stuttering text generation that users hate. By using GPU-aware load balancing, we can prioritize these phases differently across our fleet.
Metrics for the real world
To build a better router, you need to stop looking at CPU and start looking at these four metrics:
- Token queue depth — how many tokens are waiting to be processed? This is a much more accurate representation of “load” than simple request counts.
- KV cache utilization — GPUs have a limited amount of VRAM. The KV cache stores the “memory” of ongoing conversations. If a GPU’s VRAM is 90% full of KV cache, it literally cannot accept a large new prompt, even if it’s currently “idle.”
- Time to first token (TTFT) — this measures the latency of the prefill phase. If your TTFT is climbing, your prefill pool is congested.
- Inter-token latency (ITL) — this measures the speed of the decode phase. If this is high, your GPUs are likely memory-bandwidth constrained.
I often recommend using tools like vLLM because they expose these metrics out of the box. You can pipe these into a custom gateway that makes routing decisions based on real-time VRAM availability rather than just “is the server up?”
The prefix-aware hack: SkyWalker-style routing
Here is a secret — the most expensive part of a RAG request is often re-processing the same system prompt or long context over and over again. If you send five consecutive questions about the same document to five different GPUs, each GPU has to perform the “prefill” phase for that document from scratch.
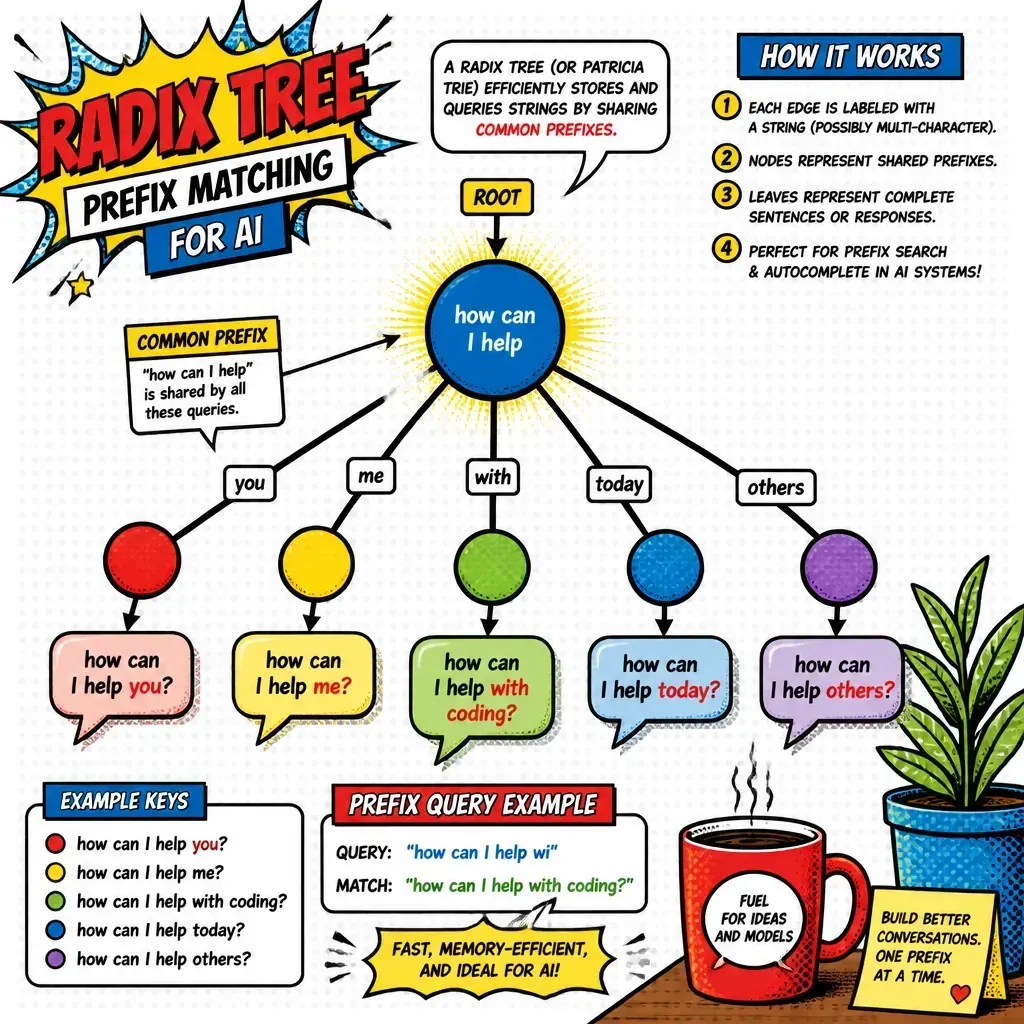
This is where prefix-aware routing (sometimes called SkyWalker-style routing) comes in. Instead of routing randomly, your load balancer tokenizes the start of the prompt and looks for a GPU that already has that specific content in its KV cache.
By matching the “prefix” of a prompt to a specific GPU, you can skip the prefill phase entirely for large chunks of text. This cuts latency from hundreds of milliseconds to almost zero. It is the single most effective way to optimize costs in production RAG systems. I’ve written before about common RAG mistakes, and ignoring cache locality is definitely one of them.
Splitting the fleet into specialized pools
As you scale, you should stop treating every GPU as a generalist. A senior move is to create disaggregated inference fleets.
I like to split my GPUs into two pools:
- The prefill pool — high-compute GPUs (like H100s) optimized for processing massive amounts of context quickly. These nodes handle the initial prompt and then “hand off” the state.
- The decode pool — memory-optimized GPUs (like A100s or even cheaper L40s) that focus on churning out tokens for existing requests.
This separation lets you scale based on your specific workload. If your users are uploading huge documents but only asking for short summaries, you scale your prefill pool. If they are having long, chatty conversations, you scale your decode pool.
This is the same logic we use in modern DevOps with Coolify. You wouldn’t put your heavy database on the same tiny instance as your frontend — why would you mix your heavy prefill work with your light decode work?
Implementing your first GPU-aware router
You don’t need to build a custom engine from scratch to start doing this. Here is the practical path I follow when setting this up for a new SaaS:
- Centralize your metrics — use Prometheus to scrape vLLM or TGI metrics from every GPU node.
- Use a smart gateway — implement a middleware in Go or Rust (or even a heavy-duty Lua script in OpenResty) that queries these metrics before choosing a target.
- Prioritize KV cache — check if the
conversation_idhas been seen by a specific node recently. If it has, and that node isn’t at 100% KV utilization, send it there. - Set hard limits — if a GPU reaches 85% VRAM usage, take it out of the rotation for new prompts until some sessions finish.
Managing AI compute is about moving from “black box” infrastructure to “context-aware” infrastructure. When your load balancer knows the difference between a 10-token greeting and a 10,000-token context window, your costs go down and your users stay happy.
It’s easy to get lost in the hype of “agentic systems” and context-aware agents, but none of that matters if your underlying infrastructure is buckling under the weight of unoptimized routing.
If you are still using round-robin for your AI models, what is the biggest bottleneck you are seeing in your P99 latency right now? Drop a note via contact — I love this conversation. 🤘