If you are running your document embeddings inside your request-response cycle, you are playing with fire. I have seen too many junior devs build a beautiful RAG application that falls over the second a user uploads a 50MB PDF. The browser spins, the Nginx timeout hits, and the database locks up while your worker tries to chunk 500 pages of legal jargon in real time.
This is the classic “heavy lifting” problem in AI engineering. Document processing — OCR, text extraction, semantic chunking, and embedding — is slow, unpredictable, and resource-heavy. Trying to force it into a synchronous web request is a recipe for a bad user experience and a fragile system.
The solution is decoupling. I’m talking about message queues. In this guide, I’ll walk you through why async work belongs in a queue and how to build a production-grade ingestion pipeline that doesn’t melt your server.
The synchronous trap
Imagine a user uploads a document to your SaaS. Your code receives the file, sends it to an extraction API, waits for the response, loops through the text to create chunks, sends each chunk to an embedding model, and finally saves it to pgvector.
If any of those steps take more than 30 seconds, the connection drops. If the embedding API has a momentary blip, the whole process fails, and the user has to start over. Worse, while your server is busy doing this heavy work, it’s not responding to other users.
This is where we apply the first rule of senior engineering: if it takes more than 100ms, consider making it async. By moving this work to a message queue, you give your users immediate feedback (“we’re processing your file!”) while the heavy lifting happens safely in the background.
The anatomy of a document pipeline
A robust RAG pipeline isn’t just one big function. It’s a series of decoupled stages. I like to break it down into modular steps, each triggered by a message in a queue. This lets you scale different parts of the system independently.
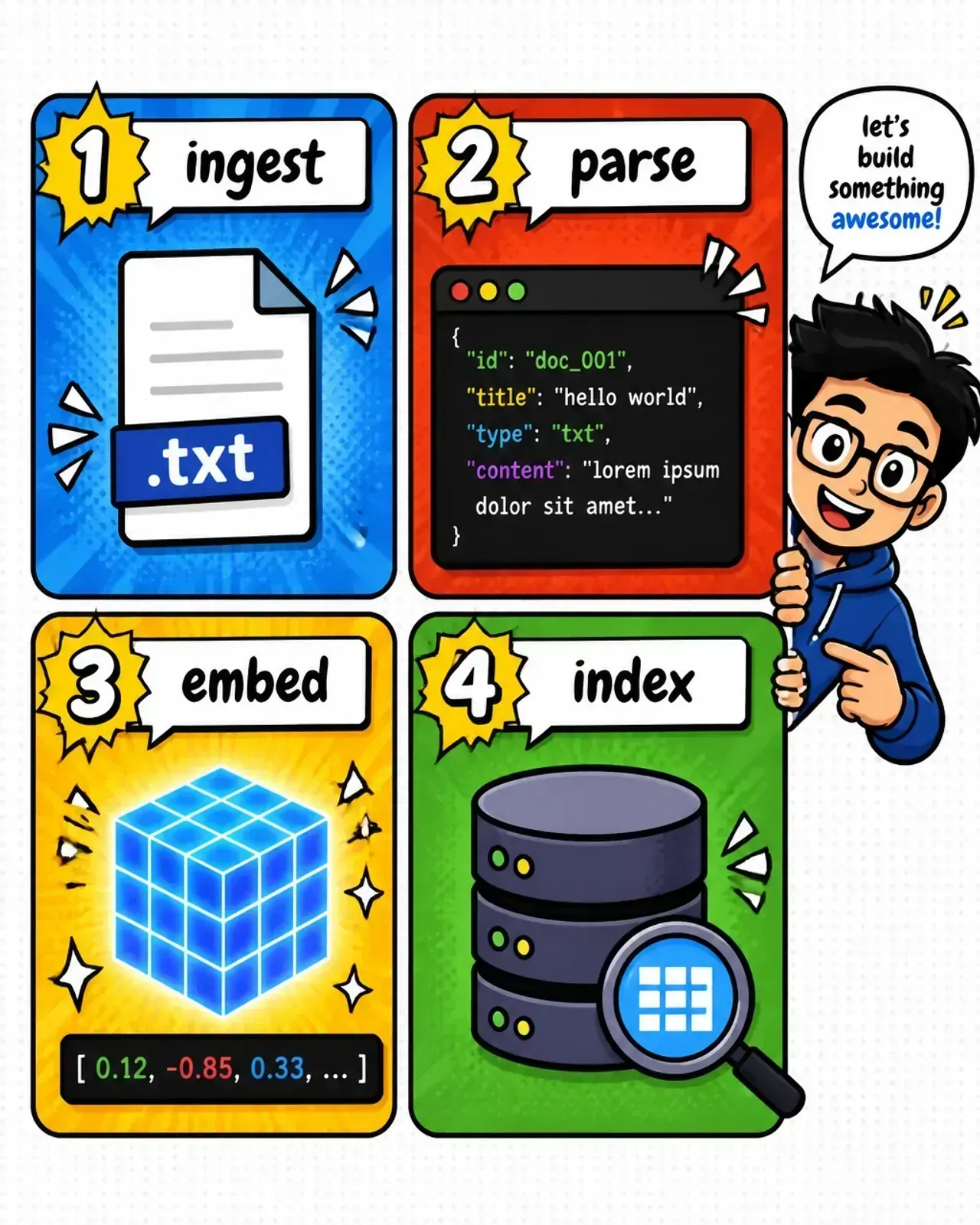
Here is how I usually structure it:
- Ingestion & discovery — a user uploads a file. You save it to S3 and push a small message to the queue containing the
file_pathandtenant_id. - Parsing & normalization — a worker picks up the message, downloads the file, and runs it through a parser like pdfplumber or an OCR service. It emits the raw text to the next queue.
- Chunking — this worker takes the text and splits it into semantic sections. Doing this in its own stage means you can easily swap chunking strategies (e.g., recursive character vs semantic) without re-running the heavy parsing step.
- Embedding & indexing — the final stage batches the chunks, hits your embedding API (like OpenAI or a local model), and pushes the vectors into your vector DB.
This stage-based approach is exactly what I discuss in my post on 7 RAG mistakes to avoid in production. It provides backpressure control — if your vector DB slows down, the “index” queue grows, but the “parsing” workers keep humming along.
Retries and the beauty of dead letters
In the real world, things break. APIs time out. PDFs are malformed. Workers crash.
When you use a message queue like Redis (with BullMQ or Laravel Queues) or SQS, you get retries for free. If a worker fails, the message goes back onto the queue to be tried again after a short delay. Exponential backoff is your best friend here — don’t hammer a failing API every 5 seconds. Wait 10, then 60, then 300.

But what happens when a document simply cannot be processed? Maybe it’s a password-protected PDF or a corrupted file. You don’t want it retrying forever and clogging up your workers.
This is where a Dead Letter Queue (DLQ) comes in. After a certain number of failed attempts, the message is moved to the DLQ. This acts as a “quarantine” zone. I can then inspect these failed jobs, fix the underlying issue, and manually re-queue them. It’s a safety net that keeps your main production line moving.
Batching for efficiency
If you are processing 10,000 chunks, you do not want to make 10,000 individual API calls to your embedding provider. That’s slow and expensive.
Most embedding APIs and vector databases perform much better with batches. A good worker pattern involves pulling multiple messages from the queue (or aggregating them in memory) and sending them as a single bulk request.
In a Laravel environment, I often use job batching to track the progress of a large document. I can see exactly when 95% of a PDF is processed and update a progress bar for the user. If you’re interested in how this fits into a larger architecture, check out my thoughts on event-driven pub/sub systems.
Event-driven prefetching
Here is a “senior” tip — queues aren’t just for ingestion. You can use them for prefetching.
If a user is chatting with an AI agent and the conversation is heading toward a specific topic, you can fire off a background job to fetch related documents and warm up the cache before the user even asks the next question. This makes your AI feel lightning fast because the context is already “ready” when the retrieval step hits.
By using an event bus, you can decouple the chat interface from these optimization tasks. The chat app just emits a user_asked_question event, and a background worker decides whether it should pre-fetch more data or update the semantic cache.
Monitoring the heart of your app
Once you move to a queue-based system, your most important metric is no longer just “request latency.” You need to watch your queue depth.
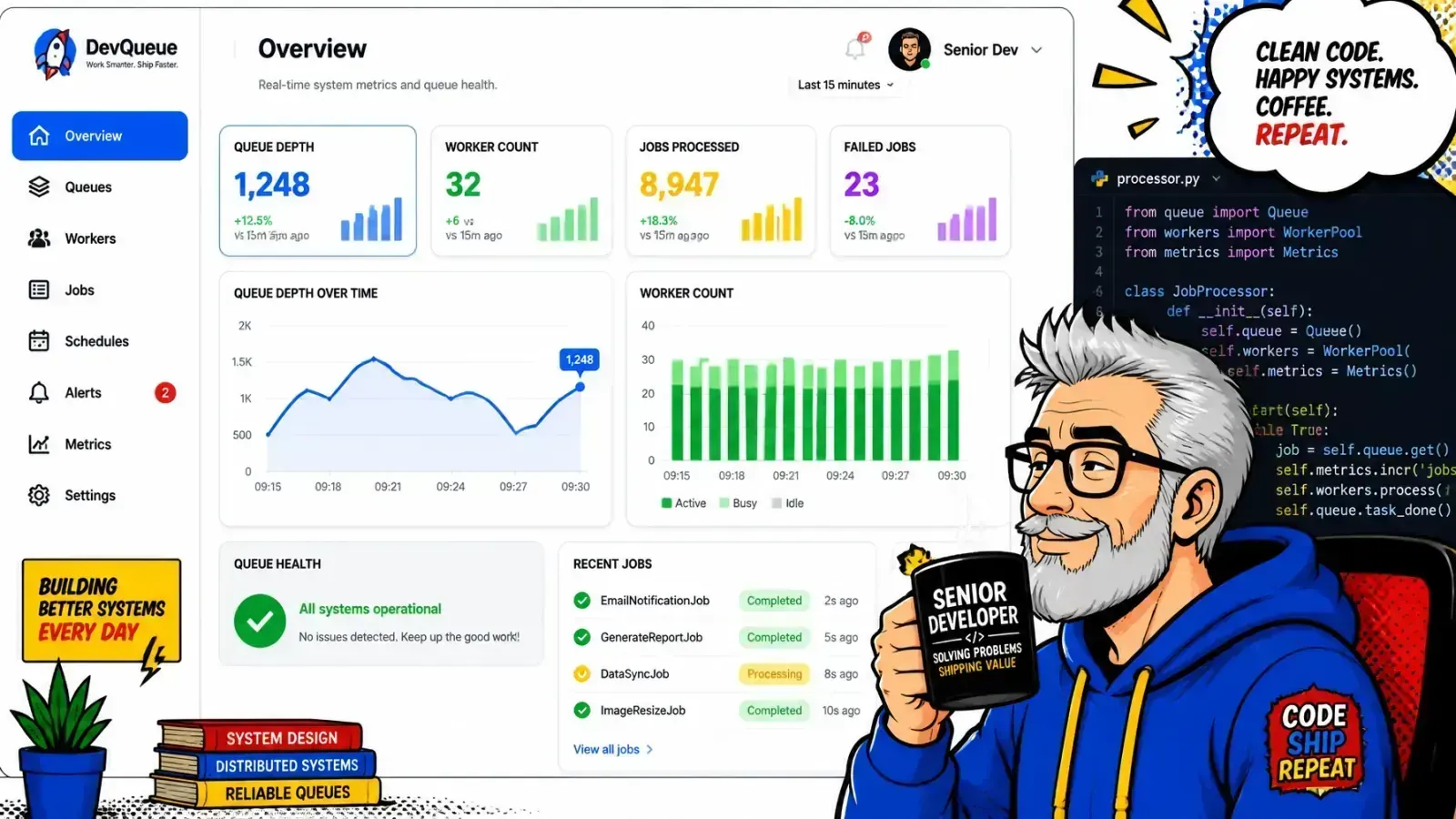
If the queue depth is growing faster than your workers can clear it, you have a bottleneck. This is where tools like Docker and Coolify make life easy — I can spin up five more worker containers to handle a sudden surge in document uploads. You can read more about how I manage this infra in my Coolify and Docker guide.
Practical takeaways for your pipeline
- Never store large files in the queue — only pass references (like an S3 key). Keep messages small for better performance.
- Make tasks idempotent — assume a message might be processed twice. Use
upsertinstead ofinsertin your vector DB to avoid duplicates. - Use structured logging — every worker log should include the
doc_idandtenant_id. Searching for “why did this file fail?” is impossible without it. - Scale on queue depth — set up your autoscaler to add workers based on how many messages are waiting, not just CPU usage.
- Separate worker pools — have one set of workers for “fast” tasks (like metadata updates) and another for “slow” tasks (like OCR/embedding). Don’t let a huge PDF upload block a simple name change.
Building a document pipeline is about respecting the time it takes to process data. By moving that work into a queue, you build a system that is resilient, scalable, and — most importantly — provides a smooth experience for your users.
How are you currently handling long-running AI tasks? Are you still fighting with request timeouts, or have you embraced the queue? Drop a note via contact — I love this conversation. 🤘